Table Of Content
The validation process of the predictive method will be carried out, taking into account what is proposed by Hernández-Julio et al. [55] to provide methodological rigour to the study. In this sense, Morse and Chung [10] and Tashakkori and Creswell [26] agreed that social science studies conducted using mixed methods provide greater certainty in research results. According to O’Cathain [27], this robustness is derived from the integration as the core of mixed-methods exercise due to the cross-referencing of multiple sources of information. On the other hand, following Uprichard and Dawney [6], who outlined critical debates about integrative positions, we argue that all mixed methods research generates “cuts” that may or may not be coherent.
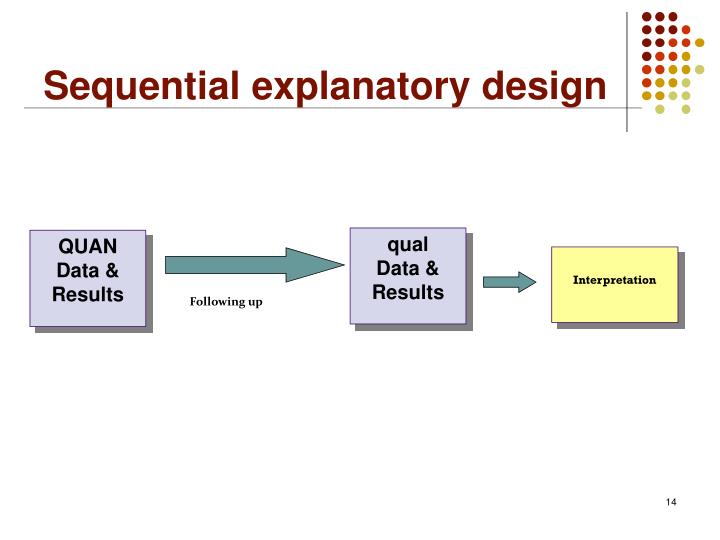
How to Construct a Mixed Methods Research Design
The process for categorising these codes involved reference to the questions, where a code-synthesis and categorisation process was applied consistently with the process described by Adu [49], as shown in Figure 2. The QUAN data was numerical, and the coding was performed in the survey questionnaire itself, making further coding post-data collection unnecessary. After the model fit criterion is met, further statistical analysis deals with the model variables and targets how the model variables behave when correlated to each other.
Sequential Bayesian-optimized graphene synthesis by direct solar-thermal chemical vapor deposition Scientific Reports - Nature.com
Sequential Bayesian-optimized graphene synthesis by direct solar-thermal chemical vapor deposition Scientific Reports.
Posted: Tue, 13 Feb 2024 08:00:00 GMT [source]
Design as a sequential decision process
This type of design is often used for studies of unspecific problems with unknown variables [3] (see Figure 3). An advantage of this type of design is the definition of the stages, which are clear and differentiated. However, an obvious disadvantage is that the qualitative stage must be carried out by a researcher with extensive knowledge of the phenomenon, identifying the emerging categories for an adequate conceptualisation [38].
Cross-Sequential Research
However, it is recognised that data integration can sometimes be problematic due to the object of the research itself, which is ontologically unstable and may not be delimited. Therefore, such messy empirical cuts can be resolved through data di-fractionation using fuzzy logic, allowing for more analytical-predictive density. The first three steps (1–3) help us to better understand the specific domain and possible gaps in existing models for evaluation.
First, according to Flick, the interview-based QUAL methodological technique is suitable for resolving unresolved issues and developing and extending ideas based on such discoveries [7]. Interviews generate extensive data that allows subdomains of ideas to be studied. Furthermore, interviews are a direct data-collecting approach that is optimum for understanding issues’ complexity and depth. These collected ideas stemming from the rich data collected are used to reinforce the hypothesis [8]. When referring to the survey QUAN methodological approach, Bajpai [9] asserts that primary sources of data provide multitudes of benefits; it is noted that primary findings are frequently pertinent to the research objectives since they are collected on an individual basis.
A Multi-faceted Mess: A Review of Statistical Power Analysis in Psychology Journal Articles
New methodological approaches aim to account for science holistically for those study phenomena that involve higher levels of complexity through epistemic pluralism [2]. Pragmatism is the philosophical connection of mixed methods, based on the worldview of actions, situations, and consequences, rather than antecedent conditions (as in post-positivism), which is concerned with applications (what works) and solutions to problems. When you want to see how people change over a lifetime, like comparing people who are 20, 40, 60, and 80 years old, you really only have two good options.
That is, many of those born in 1930 probably did not complete high school; those born in 1960 may have high school degrees, on average, but the majority did not attain college degrees; the young adults are probably current college students. And this is not even considering additional factors such as gender, race, or socioeconomic status. The young adults are used to taking tests on computers, but the members of the other two cohorts did not grow up with computers and may not be as comfortable if the intelligence test is administered on computers.
The following steps belong to the levels before the iterative design and development of data-driven decision support systems (steps 4–5). The following steps contain the iterative design and construction of data-driven decision support systems (steps 6–9). In the next step (step 9), pivot tables explain the use of this resource as a feature selector and the creation of the knowledge rule base, and the following steps (steps 10–11) concern the implementation and evaluation of Mamdani-type fuzzy data-driven decision support systems. Through the mentioned framework of the study and that proposed by Arfi [31], Abadeh et al. [56], working with linguistic fuzzy-logical methods in the social sciences, is presented as being intended to achieve the expected results.
We again omit the details on how to derive the distribution, but as you can see, the correlation leads to a flattened bell curve, which in the independent case before was perfectly symmetrical. Also the amount of correlation is proportional to the data overlap of the stages. For example, if the first stage used 5 instead of the 10 data points, the stages would be less correlated and therefore the bell curve less flattened. From the QUAL study, 387 (43 × 9) responses were collected and transcribed verbatim, then coded into 86 codes (74 deductive and 12 inductive) and 23 anchor codes. From the QUAN study, 7826 (43 × 182) responses were collected and transcribed, and then 43 codes (ordinal, 5-point Likert scale) were developed for the data for analysis.
Since longitudinal research happens over a period of time (which could be short term, as in months, but is often longer, as in years), there is a risk of attrition. Participants may move, change their phone numbers, die, or simply become disinterested in participating over time. Researchers should account for the possibility of attrition by enrolling a larger sample into their study initially, as some participants will likely drop out over time. There is also something known as selective attrition—this means that certain groups of individuals may tend to drop out. It is often the least healthy, least educated, and lower socioeconomic participants who tend to drop out over time. That means that the remaining participants may no longer be representative of the whole population, as they are, in general, healthier, better educated, and have more money.
Percentage Agreement and Holsti’s Method lack the consensus of probability that this metric, which considers the weight of the collective viewpoints, gives [60]. Landis and Koch [61] used comparative intensities in the attained coefficient to show the gauge of acceptance in reliability while utilising Scott’s Pi. Even though the technique supplied by these authors is optional, it provides good guidance and a benchmark for assessing the robustness of intercoder efficiency when employing both Scott’s Pi and Cohen’s Kappa. Table 4 shows the approach by Landis and Koch [61] in the acceptance criteria of the achieved coefficients.








No comments:
Post a Comment